
CHECK OUT THE CODE FOR THIS HERE INCLUDING AN EASY TO FOLLOW RMARKDOWN DOC HERE
I listened to an excellent episode of the Locked On Fantasy Basketball Podcast (YouTube, Apple Podcasts, Spotify) yesterday hosted by Josh Lloyd. Basically, in the fantasy basketball world players are ranked by z-scores (aka standard scores) of their core stats. The problem is that a lot of stats aren’t amenable to z-scores because they are highly non-normal. In this short blog post I want to demonstrate a simple way to compute “pseudo z-scores” using other distributions which are more useful than naively using z-scores for highly non-normal data. This isn’t the best way to do this, but it’s quick and easy.
As a specific example, Josh discusses blocks. Blocks data looks roughly like this (I don’t have blocks data easily on hand so I’m fudging with [block percentage] times [minutes played], it’s close enough for this blog post).

If you do your standard score of (x - mean[x]) / sd(x) you get this z-score table which looks really similar to the overall distribution.
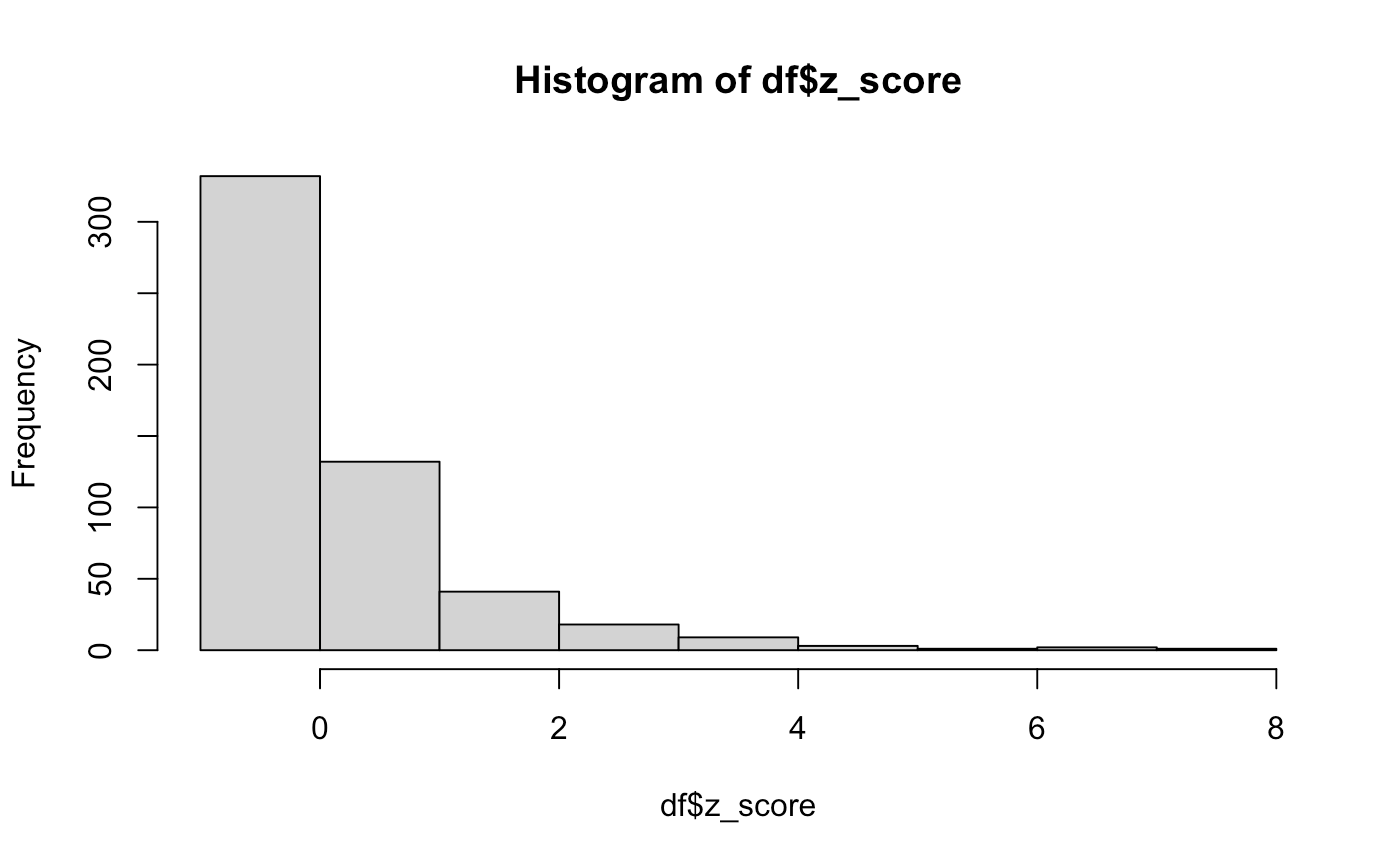
As Josh smartly notes in the podcast, the minimum z-score here is not that small. In my example it’s -0.73, which implies that like 20% of the observations should be lower… but they can’t be lower because the original variable has a minimum of zero! You can’t have negative blocks.
a quick solution
Here’s a simple way to deal with this. Instead of modeling the variable as normal (which is wrong), we can pick a more appropriate distribution. In this blog post I’ll pick the exponential distribution which looks like this (photo from Wikipedia).

We get to pick a rate parameter λ (lambda). This parameter controls the shape of the distribution. I’m just picking the exponential distribution because it has a roughly similar shape to the histogram of blocks above.
Let’s estimate our exponential distribution by starting with β = mean(blocks) which implies that λ = 1/β = 1/mean(blocks). Then, let’s do a sanity check by drawing samples from exp(1/λ) and plotting vs the data. The data is purple and the model is yellow.

It’s not perfect but it’s fine for a first pass!
OK now we’re going to do a little sorcery. We’re going to convert the observations to percentiles of the model exp(1/λ). This means we assume the model is true, and then we ask: where do the observations fall from 0 (lowest) to 1 (highest) according to that distribution.
Since we have zeros that will eventually cause problems here, we fudge by replacing zero percentiles with 0.0002. We get a plot that looks like this, which is roughly uniform with a spike at zero which is fine.

Now, we convert these percentiles to “pseudo z-scores” by saying “okay your block percentile is 0.77 what standard score would that get?”. So we get this. Pretty good!

We could do like a zero-inflated process model or whatever if we wanted to correct that zero spike but honestly it’s 10AM on Labor Day and this is fine for now. These are pseudo z-scores! Let’s compare with the original z-scores for the top blockers.

Bingo! So what we’re doing is taking JJJ’s z-score of SEVEN POINT ONE THREE and moving it down to a more reasonable 3.67. Huzzah! So now like JJJ is in the 99th percentile not in the 99.99999th percentile (not an actual estimate just a BOTE).
I hope this is useful for the basketball community. Counting stats are weird, you have to pick the right distribution!